
Datalab develops small AI models to power 'document intelligence' in the enterprise
Because bigger isn't always better

Welcome to Forkable’s COSS Corner column, where I profile startups and key figures from the commercial open source software (COSS) space.
In this edition, I check in with Vik Paruchuri and Sandy Kwon, founders of a fledgling open source startup that’s developing “AI for document intelligence.”
Datalab, as the company is called, trains smaller, specialized foundation models capable of transforming complex documents into machine-readable structured data at scale.
“Much of humanity’s collective knowledge is still trapped in complex documents like PDFs,” explained Kwon, Datalab’s chief operating officer. “If AI can’t accurately extract that data, it can’t be trusted to act on it.”
To drive its open source project development and the overarching commercial product, Datalab is also announcing a $3.5 million seed round of funding.
Read the interview in full below.
Drawing data from document disorder

By now, everyone is well-aware of the large language model (LLM) revolution ushered in by the likes of OpenAI, Google, et al: general-purpose reasoning and text generation across multiple domains.
But not every problem needs a resource-intensive, billion-parameter model that’s expensive to run and which may hallucinate on more domain-specific tasks. Small language models, custom-built for specific tasks, can offer greater benefits in terms of speed, cost, accuracy, and efficiency versus their LLM counterparts.
And this is where Datalab enters the fray.
Founded out of Brooklyn, New York, in June 2024, Datalab trains its own specialized foundation models to extract structured data from documents, with optical character recognition (OCR), layout understanding, and multilingual support embedded from the get-go.
“LLMs are incredible general-purpose tools, but most companies building on top of them are building a thin UX layer over someone else’s technology,” Paruchuri, Datalab’s CEO, said. “By training our own models, we solve challenges LLMs weren’t built for, while unlocking speed, cost efficiency, and long-term independence.”
Datalab says its training data comes either from public sources, or is created synthetically. “We never train on customer data,” Kwon added. “All of our training data is curated or generated internally.”
Datalab continues a common theme that permeates many of the startups that have pitched me at Forkable — broadly, it’s all about knocking data into shape for AI applications.
Much like how a human might combine both existing knowledge and fresh information to respond to a question usefully, AI too relies on similar data streams.
“AI is only as useful as the data it has — both in pre-training and in inference,” Paruchuri added. “Most data is in a format AI can’t use — for example PDFs or images. We unlock that data in a way that is fast and reliable.”

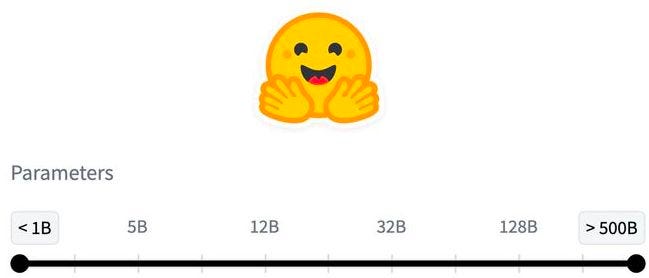
Datalab’s domain, specifically, is already well-catered to, of course. This includes everyone from legacy OCR players such as ABBYY through products from all the big tech behemoths, such as Microsoft’s Azure Document Intelligence. But Datalab is all about the diminutive — its models sit in the 100-500 million parameter range, making them fairly adept at handling complex tasks in specific domains (they’re ‘small’, but not too small), while still being able to run on consumer-grade GPUs. For context, general purpose LLMs from the likes of Open AI, Google, and Anthropic can have well over 100 billion parameters.
“We train our own very small models that inference quickly, minimize hallucination risk with custom architecture, are very accurate, and do things that LLMs can’t, like tell you exactly where in the document a piece of information is,” Paruchuri said. “We basically combine the accuracy and flexibility of LLMs, with the speed and limited hallucination-risk of older OCR tools.”
Despite being just one year old, Datalab already sports a number of high-profile logos on its homepage, including that of $61 billion AI juggernaut Anthropic. While Kwon confirmed that Anthropic is a customer, she said that they’re not able to share any details beyond that for contractual reasons.
However, as Datalab starts to ramp things up commercially, the company today announced that it has raised $3.5 million in a seed round of funding led by Pebblebed, an early-stage fund launched by some of the founding members of OpenAI and FAIR (Facebook’s AI research team). Other participants in the round include Peak XV, which is Sequoia Capital’s investment vehicle for India and Southeast Asia; and angels including Balaji Srinivasan, Jeff Hammerbacher, and founding members of AI developer platform Hugging Face.
As an interesting aside, Hugging Face this week announced a new feature that allows users to find the best model based on its size — a sign, perhaps, that the “smaller is sometimes better” ethos is catching on.
“For years, we've been saying that bigger isn't always better for AI, and that smaller specialized models are usually faster, cheaper and more accurate for your specific constraints,” Hugging Face co-founder and CEO Clem Delangue wrote on LinkedIn. “So super happy to release the long-overdue capability of finding the best model based on size on Hugging Face.”
The open source factor
Datalab’s two core tools have garnered more than 40,000 stars on GitHub at the time of writing. This includes Surya, a toolkit that acts as the “model layer” — it handles OCR, layout analysis, and structure recognition in over 90 languages. Marker builds on Surya, composing the models for higher-level tasks such as extracting, formatting, labeling, and annotating content from a wide range of document types — for instance, it can quickly convert PDF to Markdown, including any tables and complex equations in the content.
Most of the code is available under an open source GPL license, however the underlying model weights, while ‘available’, are licensed for non-commercial use only. The long and short of this is that while anyone is free to inspect, modify, and redistribute the code (subject to the usual terms of the GPL license), they can’t use the trained models in any commercial setting without a paid license. There is a waiver in place, however, that exempt companies with less than $2 million in revenue.
“We picked this approach to enable Marker to be used widely, while asking those who can afford to pay to do so,” Paruchuri explained.
And this ethos also sits at the heart of its decision to release the code under a “copyleft” GPL license, rather than a permissive MIT or Apache license.
“This ensures that anyone who builds on our work contributes back to the ecosystem,” Paruchuri continued. “Amazon and other companies are known to fork and use similar products without contributing back. We want our repositories to be as widely accessible as possible, but [we] also need to fund development.”
Datalab offers various plans, including a free tier that allows users to self-host the open source models — this is likely best suited for personal projects, academic research, or similar non-commercial use-cases. There’s also a pay-as-you-go plan which includes a hosted API solution that companies subscribe to; and an enterprise offering that can be API-accessible or hosted on-premise — the latter, according to Kwon, being Datalab’s largest revenue generator.
“We charge enterprise customers a licensing fee that covers overhead, custom work, priority support, and so on,” Kwon said.
With a fresh $3.5 million in the bank, Datalab says it will now be doubling down on developing its foundational models, and scaling its open source community and user base.