
Terminal-Bench shows how open source raises AI evaluation standards
Plus: The CNCF is keeping itself busy, while Google preps Kubernetes for agents.

Hi folks,
The lead story this week is Terminal-Bench, charting how an open benchmark is becoming a shared standard for evaluating AI coding agents.
Elsewhere, there’s a trio of new incubating projects for the CNCF, a new execution standard for agents in Kubernetes, and more.
As usual, feel free to reach out to me with any questions, tips, or suggestions: forkable[at]pm.me.
Paul
Open issue
Terminal-Bench: Open source drives new standard for agent evaluation

Since leaving TechCrunch earlier this year, I’ve been involved in a handful of exciting projects. One of those is Terminal-Bench, a (reasonably) new open source project built to standardize how we evaluate AI agents’ real command-line abilities — and it’s quickly becoming one of the most important efforts in the space.
Terminal-Bench is a benchmark developed by Stanford machine learning scientist Mike Merrill and former Google engineer Alex Shaw, and it has rapidly become one of the most influential evaluation suites for agentic AI.
The project measures how well agents can actually use a computer through a terminal: chaining commands, navigating long workflows, and handling real system feedback. In a matter of months, it’s become a proving ground for top labs.
But the real story, from Forkable’s open source perspective at least, is how Terminal-Bench is being built. Backed by the Laude Institute — co-founded by Databricks and Perplexity co-founder Andy Konwinski — and guided by Stanford assistant professor Ludwig Schmidt, the benchmark leans heavily on community contributions. Researchers and engineers submit tasks, which the team vets to ensure high quality standards. Esteemed AI safety researcher Nicholas Carlini, and others, have already contributed a sizable share.
This openness has made Terminal-Bench a shared commons at a moment when evaluation data is strategically guarded in many quarters. Some labs treat internal evals as proprietary ingredients in model and agent training—useful, some say, for safeguarding data and reducing benchmark gaming, but a problem for others who point out that closed evals weaken transparency and comparability. Terminal-Bench goes the other way: open tasks, open methodology, and open infrastructure. With the launch of Terminal-Bench 2.0 last week, “bigger, higher-quality and harder” tasks were ushered in alongside a new framework which generalizes the evaluation environment so anyone can run reproducible, containerized agent workflows.
Much of that openness comes from the Laude Institute itself, whose approach to research has shaped Terminal-Bench from day one — and will guide the other bets it makes in the years ahead.
The folks at Laude Institute asked me to do a deep dive on Terminal-Bench, meaning I had the pleasure of chatting to many of the key people behind the project, including Andy Konwinski.
“Laude Institute is ‘open-everything’ — open model, open weights, open source, open discourse, open publications,” Konwinski explained to me. “Our bets are going to be in areas like reasoning models, open-source models, and small models — things that academics can be competitive at by taking big swings at interdisciplinary research.”
As autonomous agents move closer to real responsibility — from refactors to full system maintenance — the question becomes who sets the bar for trust. Terminal-Bench is betting that the answer is “everyone.”
As a side note, this is probably the best-looking story I’ve ever had my words wrapped in — the design, layout, and graphics are next-level!
Read more: Terminal Velocity: How Terminal-Bench became the proving ground for AI’s command-line competence
Patch notes
A trio of new incubating projects for the CNCF
The Cloud Native Computing Foundation (CNCF) has elevated three open-source projects to incubating status: Lima (a VM-based environment optimized for local container and AI workloads), KServe (a unified platform for scalable AI inference on Kubernetes) and OpenFGA (a relationship-based access control engine inspired by Google’s Zanzibar). The move signals growing production maturity and community adoption for all three.
Read more: CNCF/Lima - CNCF/KServe - CNCF/OpenFGA
A new execution standard for agents lands in Kubernetes
Agent Sandbox, introduced by Google and the Kubernetes ecosystem, is a new primitive to host autonomous AI agents securely at scale. The goal is to provide strong isolation and performance for agent code execution, recognising that running “agents” isn’t just another container workload.
Read more: Google blog
Apple open-sources Embedding Atlas
Apple recently open-sourced Embedding Atlas, a tool for visualising and exploring large-scale embedding sets entirely in the browser. It allows researchers and data scientists to interactively zoom, filter and search embeddings while preserving data privacy (since everything runs locally).
Read more: Apple
Mozilla joins the Digital Public Goods Alliance
Mozilla has become a member of the Digital Public Goods Alliance (DPGA), signalling a renewed focus on open source, open data, and open AI models as “digital public goods.” Mozilla plans to advance open source tooling and funding for projects that align with broader societal impact and accessibility.
Read more: Mozilla blog
Sim slurps up $7M for open source AI workflow builder
Sim quietly announced a $7 million round of funding to scale its open-source AI-agent workflow builder.
Read more: Sim on X
And finally…
Jack’s Di-Vine intervention
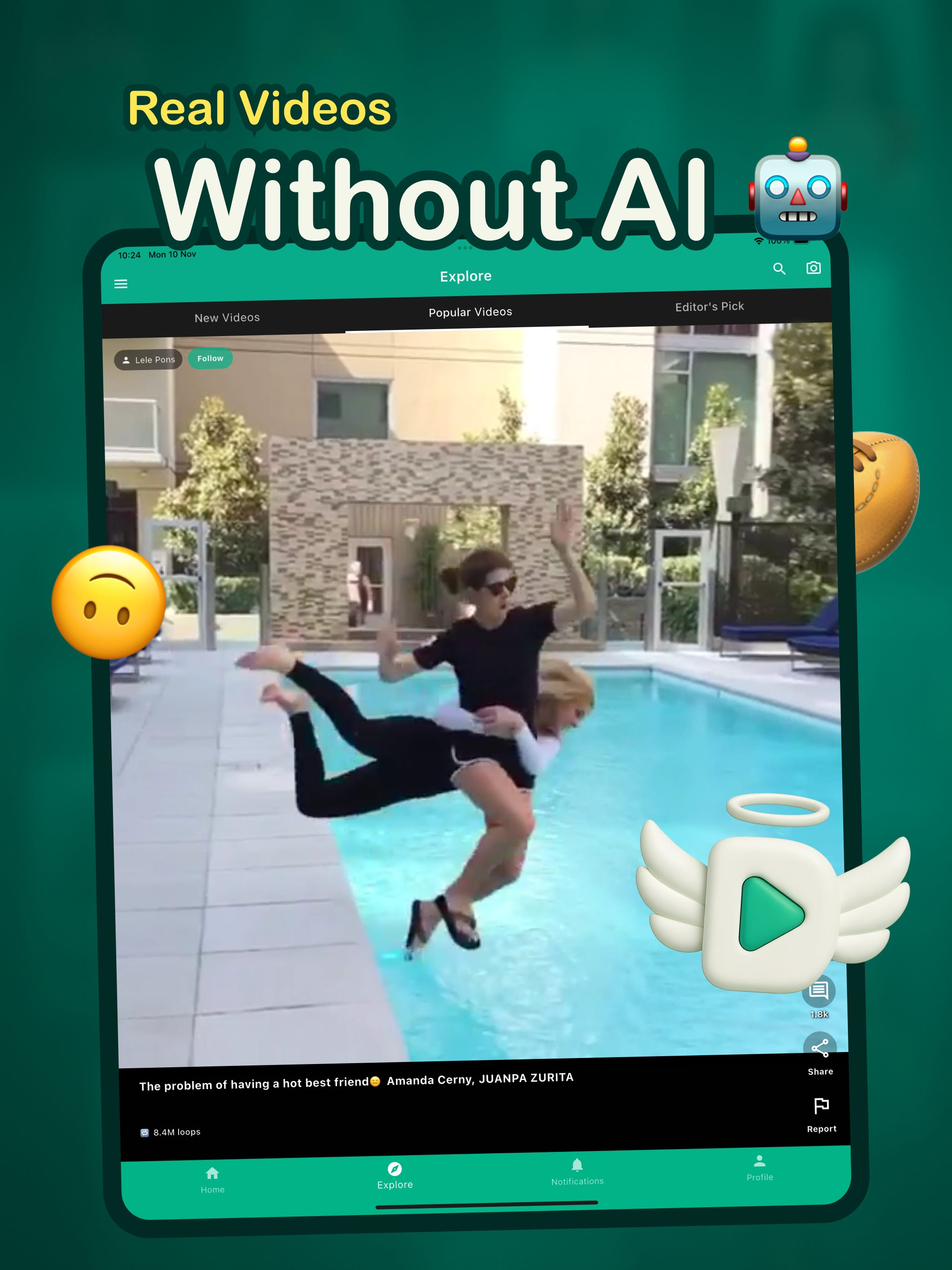
A new app called DiVine is resurrecting the spirit of Vine’s (remember Vine?) six-second loops by giving users access to more than 100,000 archived Vine videos alongside the ability to upload new ones.
Backed financially by Twitter co-founder Jack Dorsey via his nonprofit And Other Stuff, the project is built on the open-source protocol Nostr, enabling anyone to run their own relay or host.
The archive is drawn from a community-driven backup of Vine’s original content, reconstructed into profiles and searchable form by former early-Twitter staffer Evan Henshaw‑Plath (aka “Rabble”).
Creators still own their work and can request takedowns, while new uploads are subject to verification checks to ensure they’re human-made rather than AI.
Read more: DiVine & TechCrunch